Part II: How Elasticsearch Works Internally


In the first part of the article, we saw data structures used under the hood and some operations that are done to make text search better, in this part, we will see the High-Level Architecture of Elasticsearch. We will understand what are segments, what elasticsearch indexes are made of, what happens when a query is fired to an es cluster, and much more.
High-Level Design (TLDR):
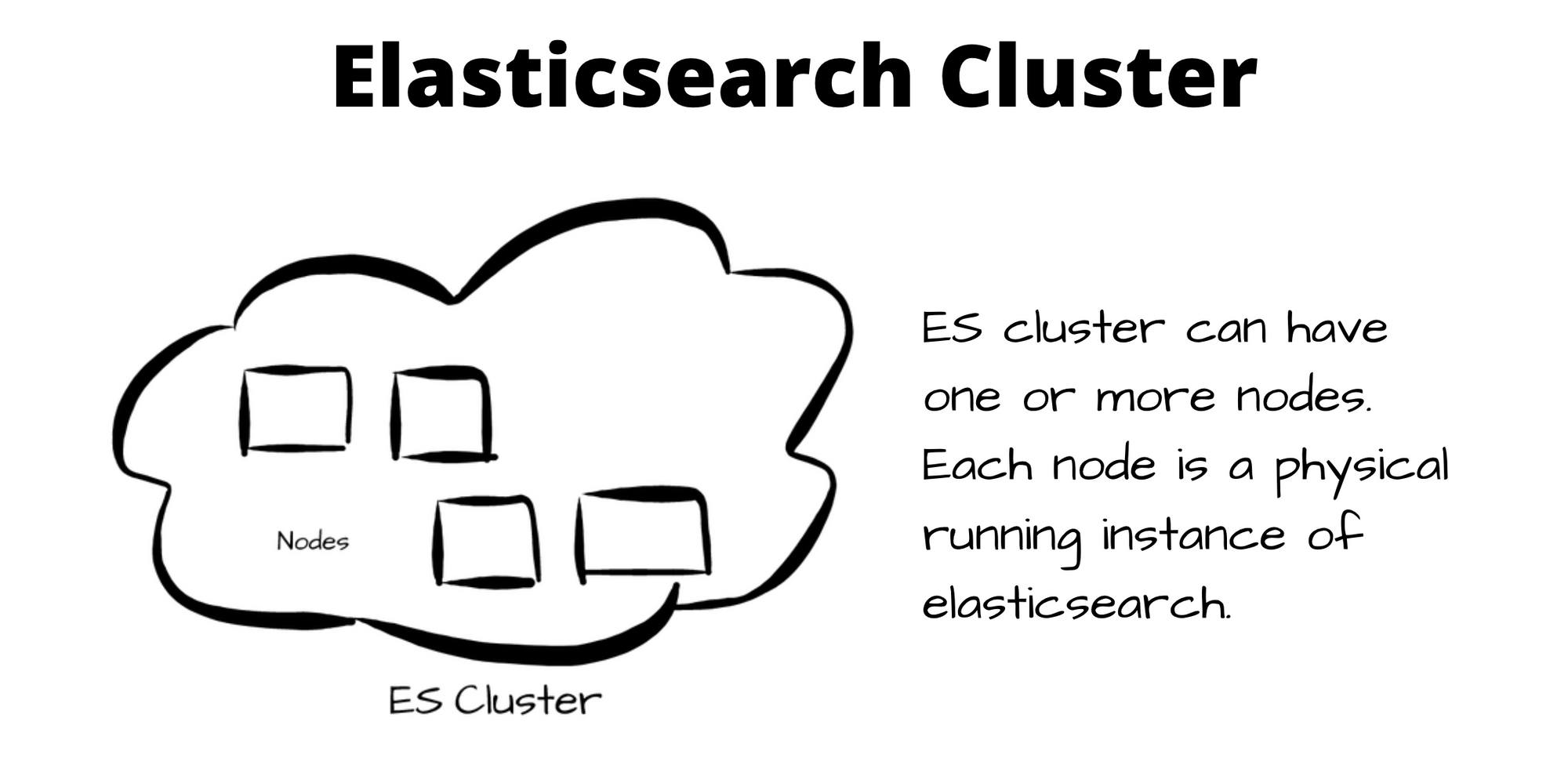
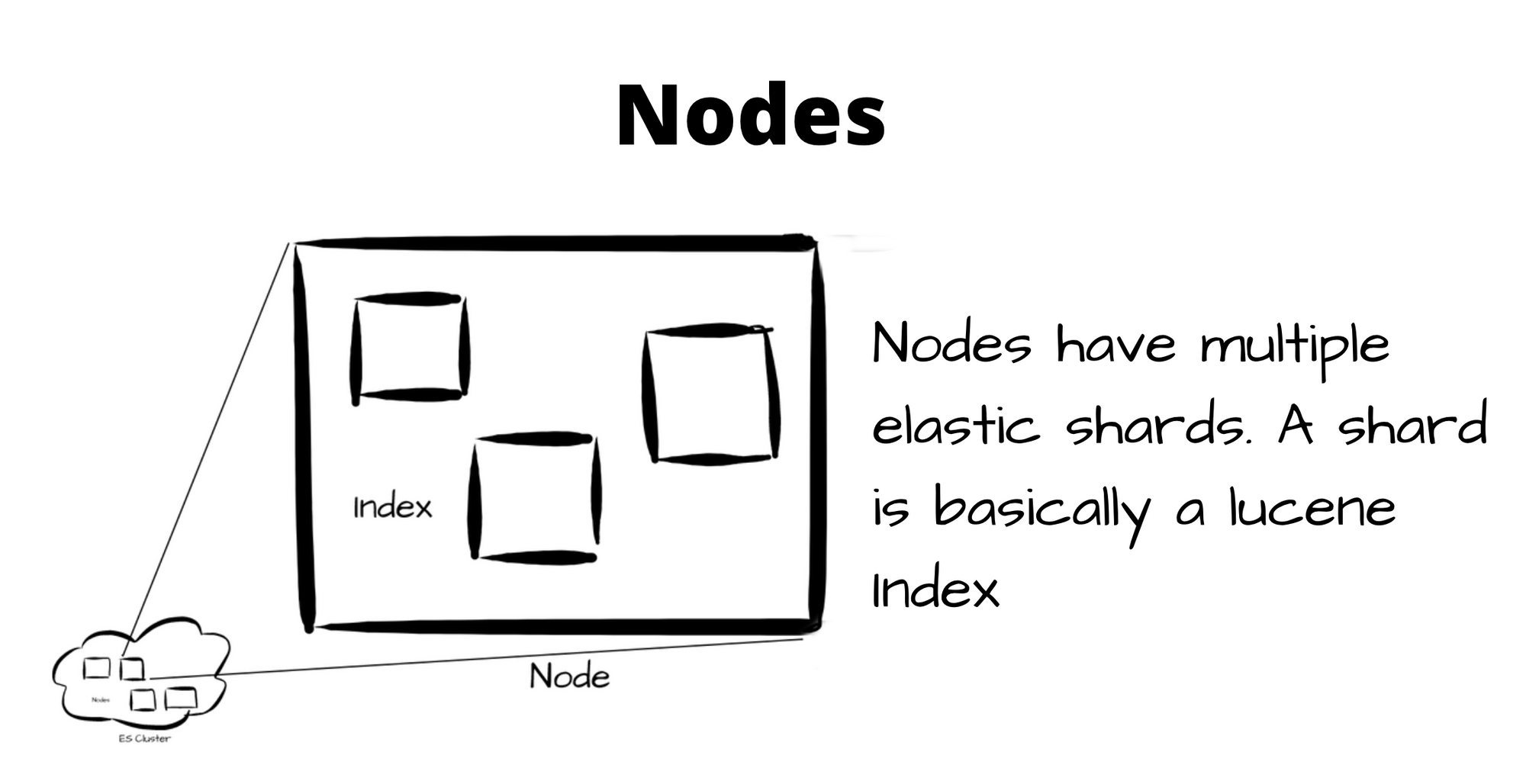
Elasticsearch clusters can have 1 or more nodes. A node is a physical instance hosting elasticsearch. A node can have one or more elasticsearch shards. Elasticsearch shards are basically Lucene index, which contains multiple immutable mini-indexes called segments. Index segments have all the data structures like stored fields, inverted index, doc-values, etc.


Details:
Before the documents are flushed into disk, documents are kept in memory and are flushed at every flush interval (defaults to 1 second). The file written on disk is called index-segment. Segments are internal storage elements in the index where the index data is stored, and are immutable in nature i.e. segments do not get updated with new documents, rather new segments are created by merging existing segments. Read more on merging here: https://www.elastic.co/guide/en/elasticsearch/reference/7.15/index-modules-merge.html
Documents are available for searching once they are flushed as segments. This operation is called a refresh - and is often costly, and calling it often while there is ongoing indexing activity can hurt indexing speed. By default, Elasticsearch periodically refreshes indices every second, but only on indices that have received one search request or more in the last 30 seconds. Read more here: https://www.elastic.co/guide/en/elasticsearch/reference/7.15/tune-for-indexing-speed.html
Multiple segments form one Lucene index. A Lucene index is nothing but an elasticsearch shard. When an index is created, shards are automatically created for that index, if we don't specify the no. it defaults to 5 primary shards i.e documents will be distributed to these 5 shards on the cluster.

The default replication factor for a shard is 1, meaning that every primary shard will be copied to another shard that will contain the same data. Replicas are used to increase search performance and for fail-over. A replica shard is never going to be allocated on the same node where the related primary is.
One or multiple primary or replica shards can reside on a node and there can be one or more nodes in an elasticsearch cluster. /_cluster/state/ API can be used to get no. of nodes in an es cluster.

As of now, we have seen the high-level design and components of elasticsearch, now let's understand what happens when a query is fired to an es cluster.
- When a query is fired, it can land on any node of the elasticsearch cluster, that node for this query becomes the coordinator node.
- The co-ordinator node checks for shards that need to be queried, elastic queries are converted to Lucene queries and all the segments in an elastic shard or a Lucene index are queried.
- The results from all the shards are returned to the coordinator node and subsequently returned to the client.
Conclusion:
In this article series, we learned about data structures and high-level components of elasticsearch.
Resources:
I highly recommend, watching the video and reading the articles below. This article is inspired by the below video.
Alex Brasetvik Rahul Mishra
Rahul Mishra