Redis Partitioning And Redis Cluster Local Setup


In this article, we will learn about Redis partitioning, particularly about Redis Cluster, we will understand the use-cases of partitioning. In the latter half, we will be setting up the Redis cluster locally as well.
From the official doc:
Partitioning is the process of splitting your data into multiple Redis instances so that every instance will only contain a subset of your keys.
Different implementations of partitioning:
Partitioning can be the responsibility of different parts of a software stack.
- Client-side partitioning means that the clients directly select the right node where to write or read a given key. Many Redis clients implement client-side partitioning.
- Proxy-assisted partitioning means that our clients send requests to a proxy and the proxy will make sure to forward our request to the right Redis instance according to the configured partitioning schema. The Redis and Memcached proxy Twemproxy implements proxy-assisted partitioning.
- Query routing means that the Redis client can send your query to a random instance, and the instance will make sure to forward the query to the right node. Query routing is used by Redis Cluster, in which any Redis node can receive a query and will redirect the client to the correct node.
Disadvantages of partitioning:
Some features of Redis don't play very well with partitioning:
- Operations involving multiple keys are usually not supported. For instance, we can't perform the intersection between two sets if they are stored in keys that are mapped to different Redis instances.
- Redis transactions involving multiple keys can not be used. However, we can force keys to be hashed on the same cluster using hashtag.
- The partitioning granularity is the key, so it is not possible to shard a dataset with a single huge key like a very big sorted set.
Redis Cluster:
Redis cluster is the de-facto way of partitioning in Redis. Redis clusters use hash slots for the distribution of keys. There are total 16384 hash slots in Redis Cluster, and to compute the hash slot for a given key, we need to do CRC16 of the key modulo 16384.
hash_slot = crc16(key) mod 16384Every node in a Redis Cluster is responsible for a subset of the hash slots, so, for example, we may have a cluster with 3 nodes, where:
- Node A contains hash slots from 0 to 5460.
- Node B contains hash slots from 5461 to 10922.
- Node C contains hash slots from 10923 to 16383.
Keys are written to the node containing that hash_slot. Therefore, if nodes are added or removed, then existing keys need to be re-balanced.
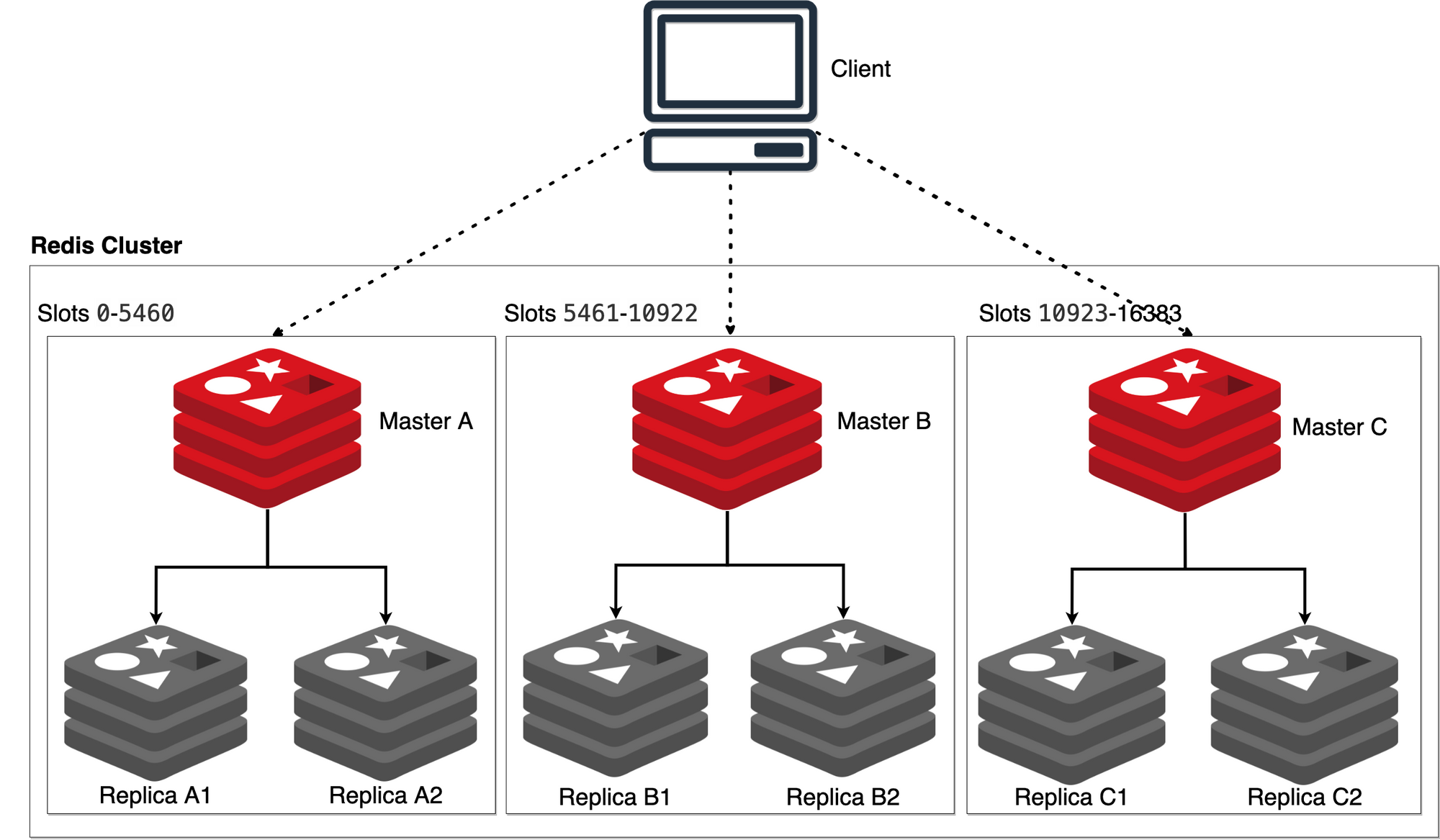
For example, if we want to add a new node D, we need to move some hash slots from nodes A, B, and C to node D. Similarly, if we want to remove node A from the cluster, we can just move the hash slots served by node A and distribute to node B and C. Note that moving hash slots from a node to another does not require stopping any operations; therefore, adding and removing nodes, or changing the percentage of hash slots held by a node, requires no downtime.
Redis Cluster does not guarantee strong consistency owing to the asynchronous replication. Master acknowledges writes to the client before propagating the writes to replicas and if the master crashes before propagating writes, then 1 of the replicas will be promoted to master which will not have the latest writes, making the cluster lose the writes.
The fix would be to have synchronous replication, ie. the master will only ack writes to the client when the majority of the replicas have confirmed the writes. Since this is blocking in nature, it will have an impact on the performance of the cluster.
There is another notable scenario where Redis Cluster will lose writes, that happens during a network partition where a client is isolated with a minority of instances including at least a master.
Redis Cluster Setup On Local:
Let's set up the Redis cluster on local, for that we need redis-server installed on your machine. We will start by creating a folder for all our cluster configs. We need a minimum of 3 masters for cluster setup. And each master should have at least 1 replica for failover and HA.
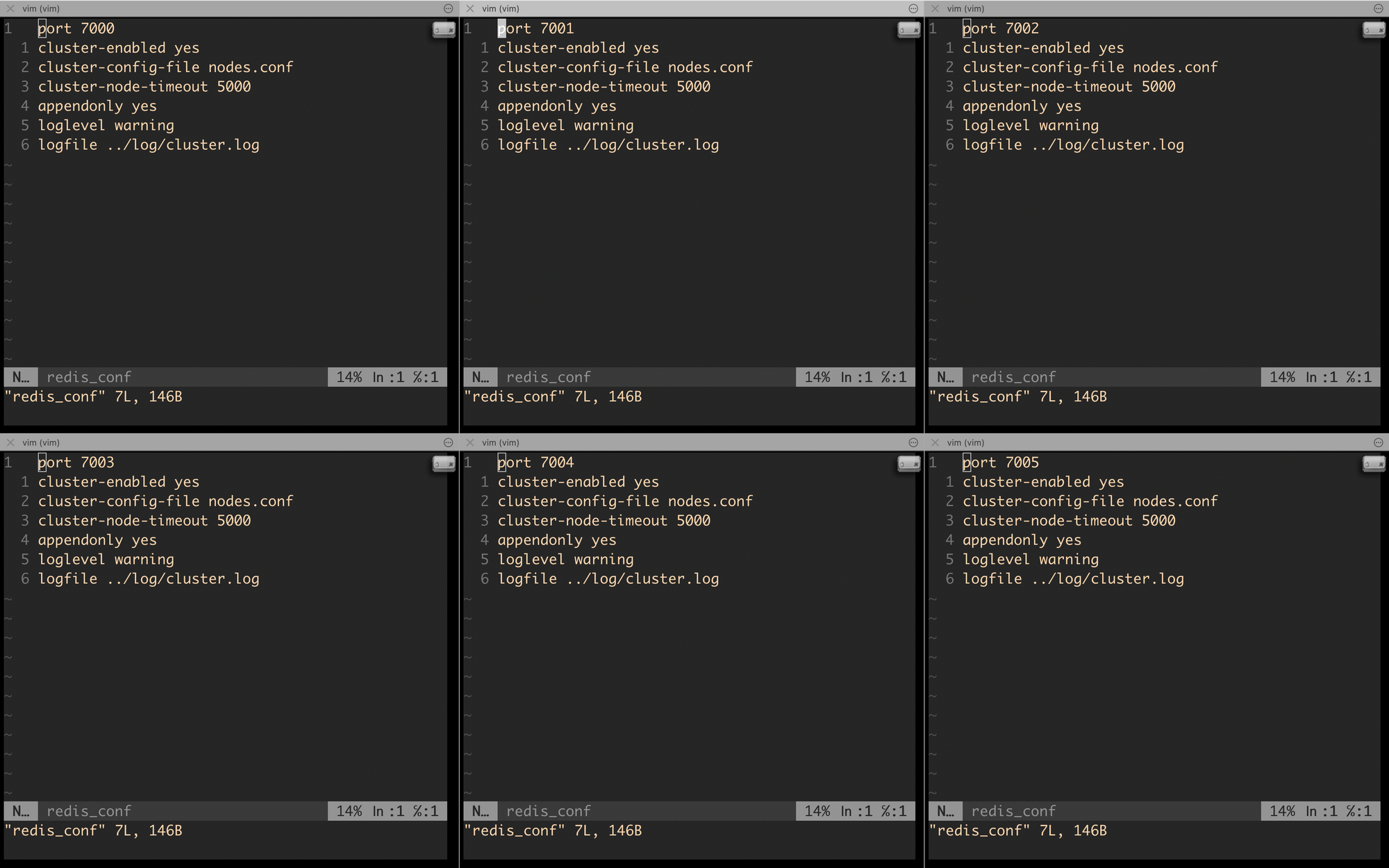
We will start by creating a folder structure and putting our cluster config in each folder.

Copy the following config in each folder. Make sure to change the port as per the directory name. i.e for directory 7003 keep port as 7003.
port 7000
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
loglevel warning
logfile ../log/cluster.log

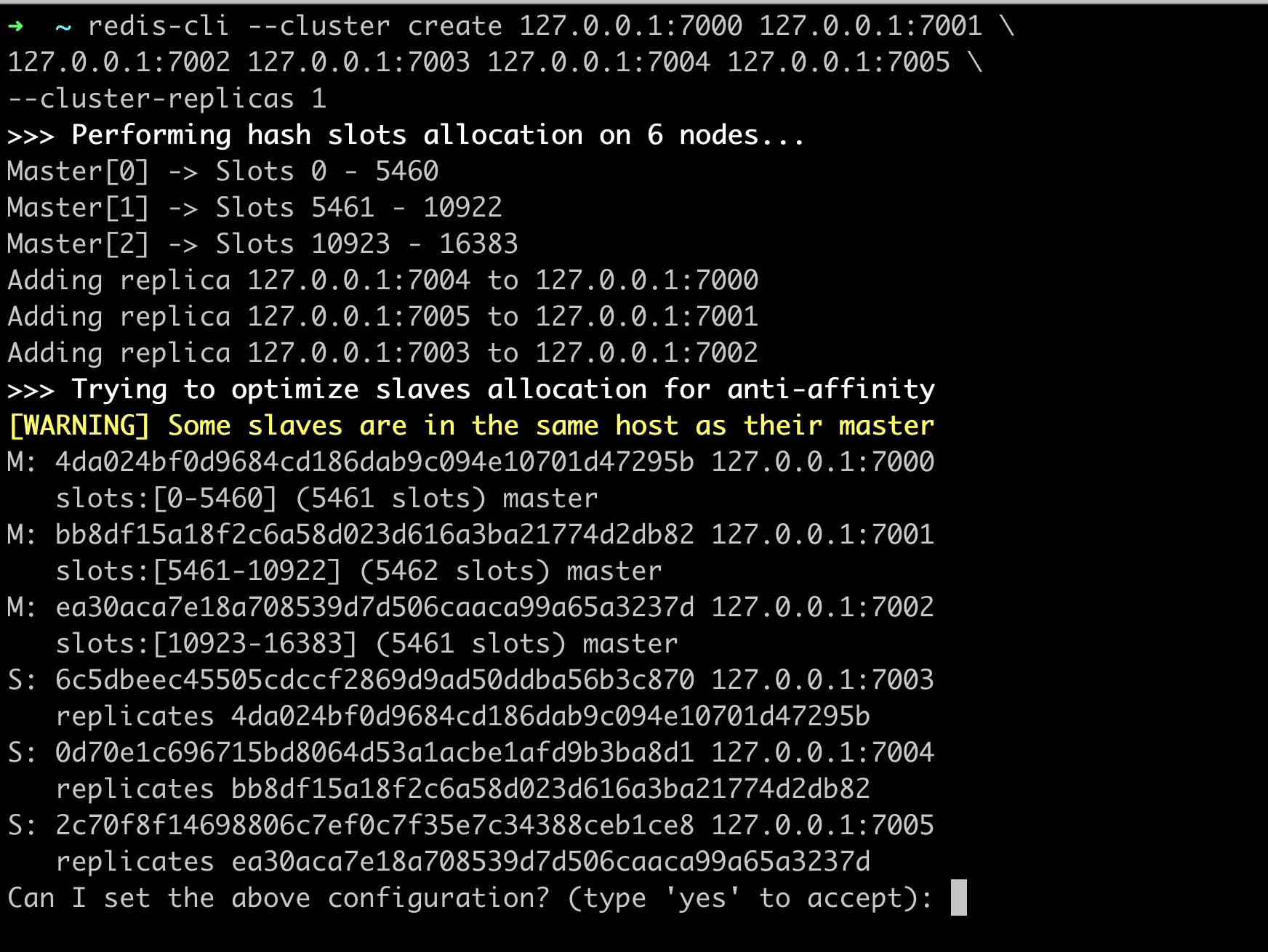
At this stage, all nodes are running, but they are not connected and are not a part of a cluster, we need to use --cluster create command to do so.
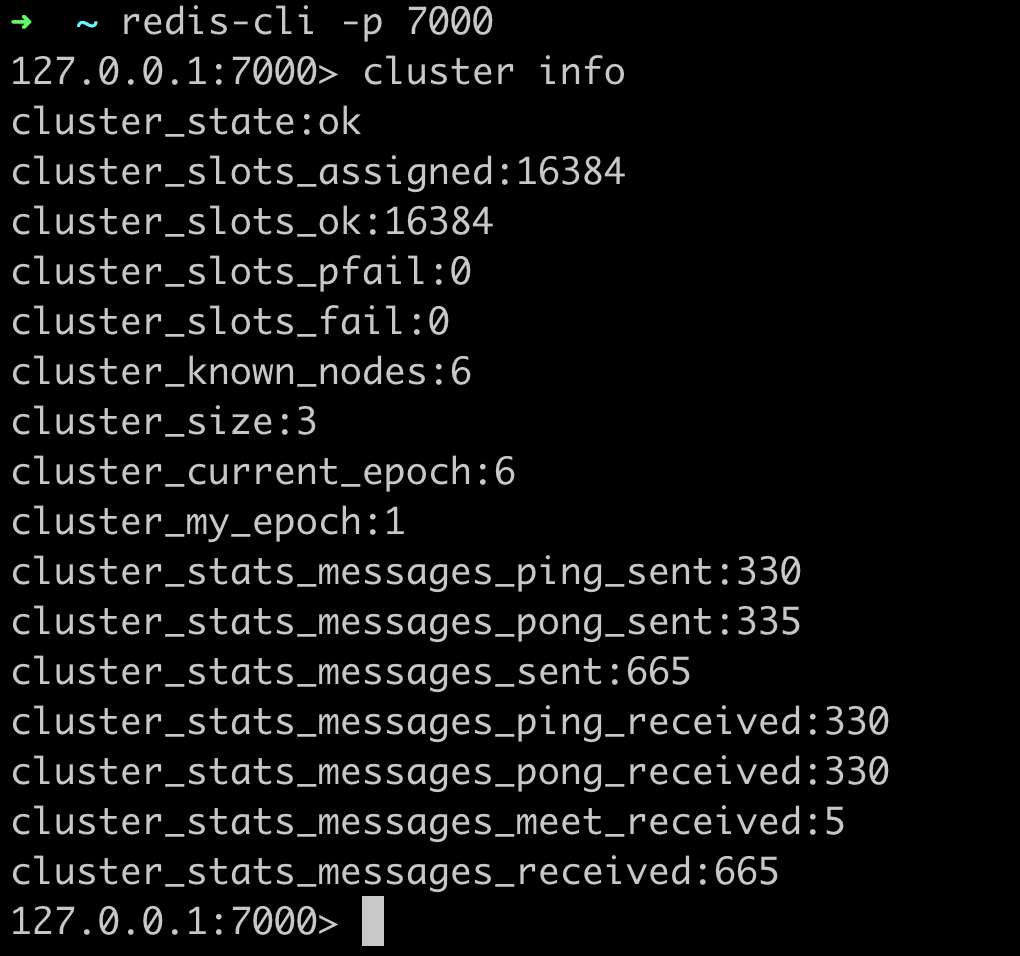
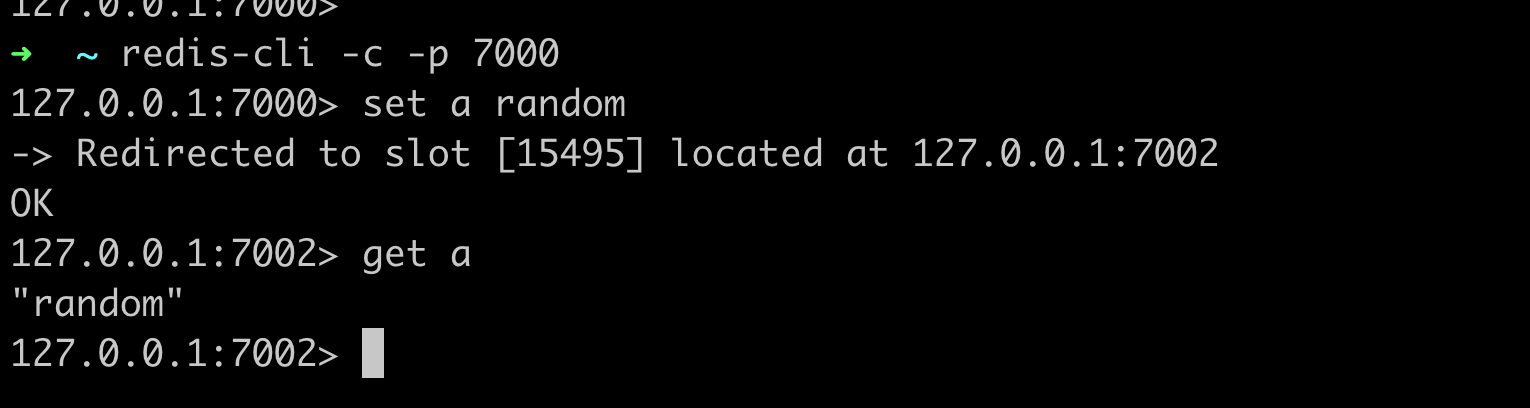
And we are done. Now we have a redis cluster running on local, lets run cluster info to see the cluster information and run some commands.
Resources:
 Rahul Mishra
Rahul Mishra